Visualizations in Tableau and Analysis¶
After cleaning and transforming the data, I exported the processed dataset from Kaggle and imported it into Tableau. In Tableau, I created various visualizations, like Pareto charts, bar charts, and line graphs, to explore key metrics such as sales performance, regional distribution, and customer segmentation. This process combined Python's data-cleaning power with Tableau's visualization features for an interactive sales analysis dashboard.
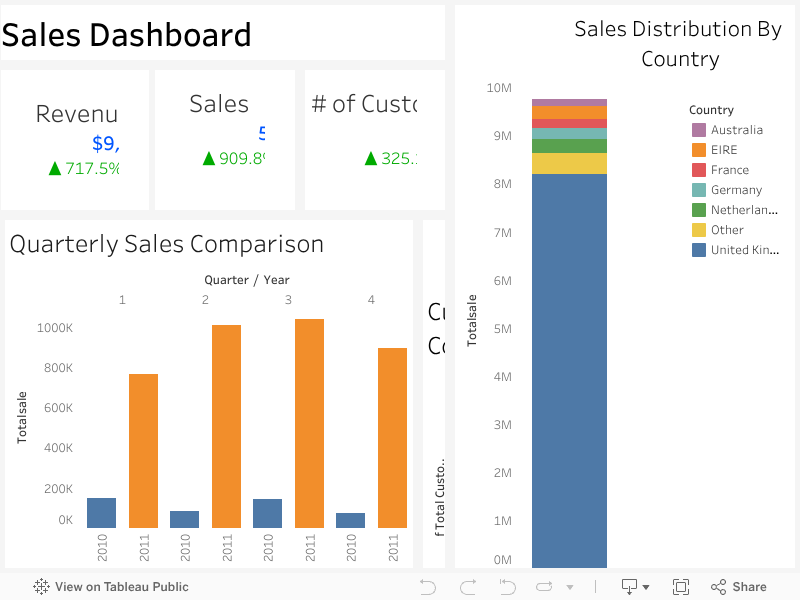
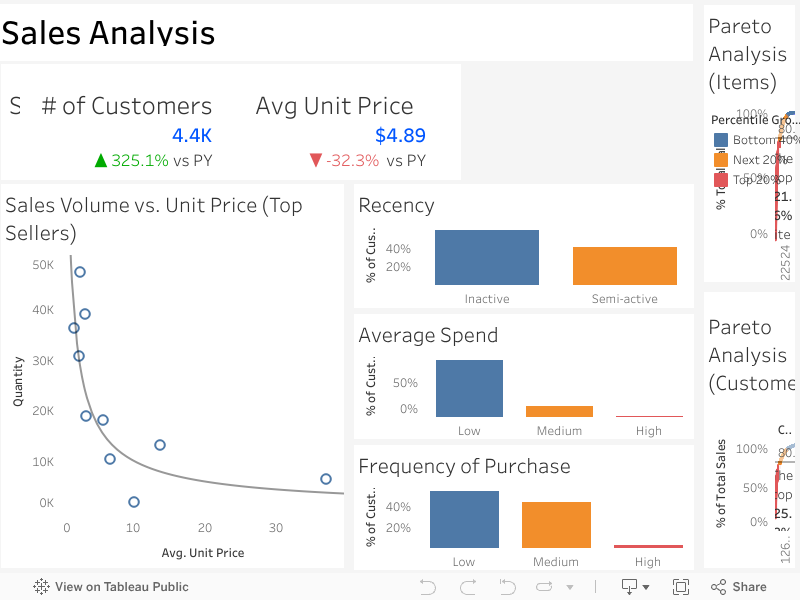
Below, I analyze each graph and state some key takeaways for the business.











